«Идеальный» www кластер. Часть 1. Frontend: NGINX + Keepalived (vrrp) на CentOS
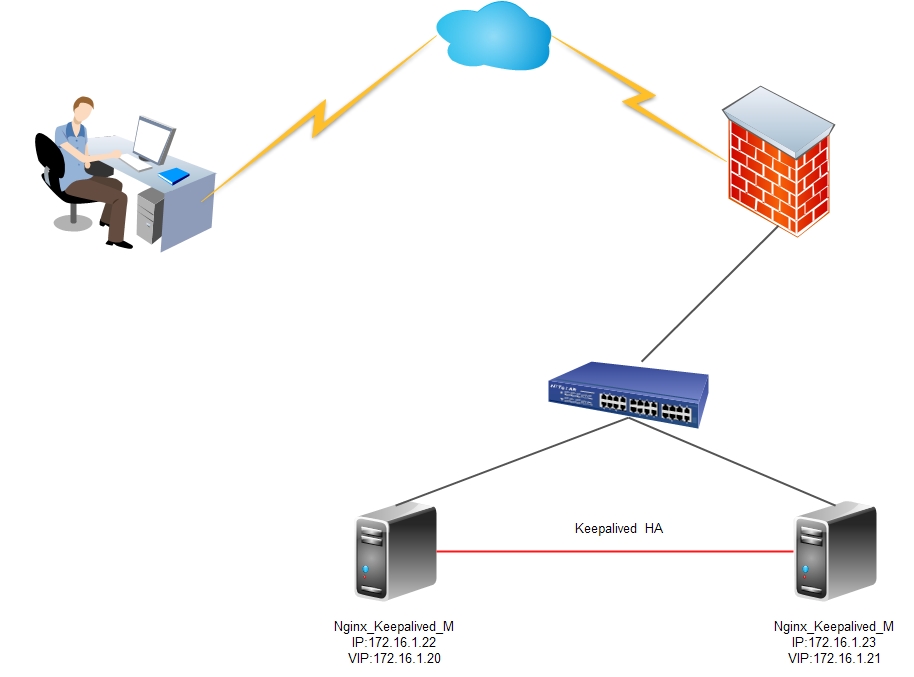
Этом цикле статей «Идеальный www кластер», я хочу передать базовые основы построения высокодоступного и высокопроизводительного www решения для нагруженных web проектов для неподготовленного администратора.
Статья будет содержать пошаговую инструкцию и подойдет любому человеку кто освоил силу copy-paste
Ошибки найденые вами, помогут в работе и мне и тем кто будет читать эту статью позже! Так что любые улучшение и правки приветствуются!
Хочу отметить, что эта инструкция родилась в процессе миграции web-систем компании Acronis в высокодоступный кластер. Надеюсь мои заметки будут полезны и для Вас!.
В процессе экспертизы и проведенных мною исследований, она доказала свое право на жизнь и благополучно служит нам верой и правдой день ото дня.
На frontend мы будем использоваться связку из двух службы:
keepalived — реализации протокола VRRP (Virtual Router Redundancy Protocol) для Linux. Демон keepalived следит за работоспособностью машин и в случае обнаружения сбоя — исключает сбойный сервер из списка активных серверов, делегируя его адреса другому серверу.
Другими словами, у нас 2 сервера на которых прописано по одному публичному адресу. Если любой из этих серверов падает, то адрес упавшего подхватывается вторым.
Демоны keepalived общаются по протоколу VRRP, посылая друг другу сообщения на адрес 224.0.0.18.
Если сосед не прислал свое сообщение, то по истечению периода он считается умершим и оба адреса обслуживает оставшаяся нода. Как только упавший сервер начинает слать свои сообщения в сеть, все возвращается на свои места
nginx [engine x] — это HTTP-сервер и обратный прокси-сервер, а также почтовый прокси-сервер, написанный Игорем Сысоевым. Уже длительное время он обслуживает серверы многих высоконагруженных российских сайтов, таких как Яндекс, Mail.Ru, ВКонтакте и Рамблер. Согласно статистике Netcraft nginx обслуживал или проксировал 15.08% самых нагруженных сайтов в октябре 2013 года.
Основная функциональность HTTP-сервера
- Обслуживание статических запросов, индексных файлов, автоматическое создание списка файлов, кэш дескрипторов открытых файлов;
- Акселерированное обратное проксирование с кэшированием, простое распределение нагрузки и отказоустойчивость;
- Акселерированная поддержка FastCGI, uwsgi, SCGI и memcached серверов с кэшированием, простое распределение нагрузки и отказоустойчивость;
- Модульность, фильтры, в том числе сжатие (gzip), byte-ranges (докачка), chunked ответы, XSLT-фильтр, SSI-фильтр, преобразование изображений; несколько подзапросов на одной странице, обрабатываемые в SSI-фильтре через прокси или FastCGI, выполняются параллельно;
- Поддержка SSL и расширения TLS SNI.
Другие возможности HTTP-сервера
- Виртуальные серверы, определяемые по IP-адресу и имени;
- Поддержка keep-alive и pipelined соединений;
- Гибкость конфигурации;
- Изменение настроек и обновление исполняемого файла без перерыва в обслуживании клиентов;
- Настройка форматов логов, буферизованная запись в лог, быстрая ротация логов;
- Специальные страницы для ошибок 3xx-5xx;
- rewrite-модуль: изменение URI с помощью регулярных выражений;
- Выполнение разных функций в зависимости от адреса клиента;
- Ограничение доступа в зависимости от адреса клиента, по паролю (HTTP Basic аутентификация) и по результату подзапроса;
- Проверка HTTP referer;
- Методы PUT, DELETE, MKCOL, COPY и MOVE;
- FLV и MP4 стриминг;
- Ограничение скорости отдачи ответов;
- Ограничение числа одновременных соединений и запросов с одного адреса;
- Встроенный Perl.

Важно! Для приведенного ниже решения, у нас должно быть 2 сетевых интерфейса на каждой из нод keepalived
мы должны точно указать нашу маску и понимать где в нашей сети находится broadcast, если этого не сделать, то будем очень долго пытаться понять почему у нас все работает не так как мы хотим!
# Моя приватная сеть
[root@nginx-frontend-01 ~]#
nano /etc/sysconfig/network-scripts/ifcfg-eth2DEVICE=eth2
BOOTPROTO=static
ONBOOT=yes
IPADDR=10.100.100.56
NETWORK=10.100.100.0
NETMASK=255.255.255.0
BROADCAST=10.100.100.255
# Публичная сеть
[root@nginx-frontend-01 ~]#
nano /etc/sysconfig/network-scripts/ifcfg-eth3 DEVICE=eth3
BOOTPROTO=static
ONBOOT=yes
IPADDR=72.x.x.1
NETMASK=255.255.255.248
BROADCAST=72.x.x.55
GATEWAY=72.x.x.49
То есть в моей публичной сети, маска /29 и значит мой broadcast x.x.x.55, если бы была сеть /24, то можно было бы указать x.x.x.255
Если это перепутать, то вы отгребете кучу проблем
# Устанавливаем keepalived
yum install keepalived -y # Это очень плохо, этого делать не нужно! только в тестовых целях и на свой страх и риск, я предупредил. Выключаем selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux # Настраиваем keepalived на первой ноде nginx-frontend-01, очень важно, знак коментария “!” а не “#”
mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.old && nano /etc/keepalived/keepalived.conf [root@nginx-frontend-01 ~]#
nano /etc/keepalived/keepalived.conf ! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
! Именное обозначение этого сервера
router_id nginx-frontend-01
}
vrrp_instance nginx2 {
! Состояние в котором стартует нода, в этом случае она резерв
state BACKUP
! Наш публичиный интерфейс
interface eth3
! Индификатор, в разных vrrp_instance он должен быть разным
virtual_router_id 102
! Это приоритет этой ноды перед другими, у BACKUP он всегда должен быть ниже чем у MASTER
priority 100
advert_int 1
dont_track_primary
! Тут можно на всякий случай указать наш broadcast
mcast_src_ip x.x.x.55
! Пароль можно указать любой, но одинаковый для серверов
authentication {
auth_type PASS
auth_pass b65495f9
}
! Этот адрес возмет себе сервер, если MASTER в сети упадет
virtual_ipaddress {
x.x.x.2/29 dev eth3
}
}
vrrp_instance nginx1 {
! Эта нода - мастер, она использует адрес из этой секции и ее заменит другая, если эта упадет
state MASTER
! Наш публичиный интерфейс
interface eth3
! Индификатор, в разных vrrp_instance он должен быть разным
virtual_router_id 101
! Для мастера это значение обязательно выше чем для backup
priority 200
advert_int 1
dont_track_primary
! Тут можно на всякий случай указать наш broadcast
mcast_src_ip x.x.x.55
! Пароль можно указать любой, но одинаковый для серверов
authentication {
auth_type PASS
auth_pass b65495f8
}
virtual_ipaddress {
! Нода стартует с этим адресом, если эта нода упадет, этот адрес подхватит другая
x.x.x.1/29 dev eth3
}
! Для мастера нужно прописать gateway
virtual_routes {
default via x.x.x.49 dev eth3 metric 2
}
}
# Настраиваем keepalived на второй ноде nginx-frontend-02 очень важно, знак коментария “!” а не “#”
mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.old && nano /etc/keepalived/keepalived.conf [root@nginx-frontend-02 ~]#
nano /etc/keepalived/keepalived.conf ! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
! Именное обозначение этого сервера
router_id nginx-frontend-02
}
vrrp_instance nginx1 {
! Состояние в котором стартует нода, в этом случае она резерв
state BACKUP
! Наш публичиный интерфейс
interface eth3
! Индификатор, в разных vrrp_instance он должен быть разным
virtual_router_id 101
! Это приоритет этой ноды перед другими, у BACKUP он всегда должен быть ниже чем у MASTER
priority 100
advert_int 1
dont_track_primary
! Тут можно на всякий случай указать наш broadcast
mcast_src_ip x.x.x.55
! Пароль можно указать любой, но одинаковый для серверов
authentication {
auth_type PASS
auth_pass b65495f9
}
! Этот адрес возмет себе сервер, если MASTER в сети упадет
virtual_ipaddress {
x.x.x.1/29 dev eth3
}
}
vrrp_instance nginx2 {
! Эта нода - мастер, она использует адрес из этой секции и ее заменит другая, если эта упадет
state MASTER
! Наш публичиный интерфейс
interface eth3
! Индификатор, в разных vrrp_instance он должен быть разным
virtual_router_id 102
! Для мастера это значение обязательно выше чем для backup
priority 200
advert_int 1
dont_track_primary
! Тут можно на всякий случай указать наш broadcast
mcast_src_ip x.x.x.55
! Пароль можно указать любой, но одинаковый для серверов
authentication {
auth_type PASS
auth_pass b65495f9
}
! Нода стартует с этим адресом, если эта нода упадет, этот адрес подхватит другая
virtual_ipaddress {
x.x.x.2/29 dev eth3
}
virtual_routes {
! Для мастера нужно прописать gateway
default via x.x.x.49 dev eth3 metric 2
}
}
# Добавляем в автозагрузку и запускаем
chkconfig keepalived on && service keepalived restart # Добавляем разрешения фаервола, больше половины проблем, из за того что мы забываем про фаервол!
iptables -A INPUT -i eth3 -p vrrp -j ACCEPT
iptables -A OUTPUT -o eth3 -p vrrp -j ACCEPT
iptables -A INPUT -d 224.0.0.0/8 -i eth3 -j ACCEPT
iptables-save > /etc/sysconfig/iptables# Это очень важный шаг
Установка этой переменной позволяет отдельным локальным процессам выступать от имени внешнего (чужого) IP адреса
echo "net.ipv4.ip_nonlocal_bind=1" >> /etc/sysctl.conf && sysctl -p # Проверяем
/etc/init.d/keepalived restart && tail -f -n 100 /var/log/messages# Проверяем как между собой общаются наши ноды keepalived
tcpdump -vvv -n -i eth3 host 224.0.0.18 # Мы должны увидеть это
x.x.x.55 > 224.0.0.18: VRRPv2, Advertisement, vrid 102, prio 200, authtype simple, intvl 1s, length 20, addrs: x.x.x.2 auth "b65495f9"
07:50:50.019548 IP (tos 0xc0, ttl 255, id 5069, offset 0, flags [none], proto VRRP (112), length 40)
x.x.x.55 > 224.0.0.18: VRRPv2, Advertisement, vrid 101, prio 200, authtype simple, intvl 1s, length 20, addrs: x.x.x.1 auth "b65495f9"
Теперь можно попеременно выключать сервера, опускать интерфейсы, дергать провода итд
У нас в сети всегда будут присутствовать оба этих адреса и на них будет отвечать наш nginx

# Подключаем официальный репозиторий nginx для CentOS 6
rpm -Uhv https://nginx.org/packages/rhel/6/noarch/RPMS/nginx-release-rhel-6-0.el6.ngx.noarch.rpm# Обновляем систему и устанавливаем nginx
yum update -y
yum install nginx # Удаляем хосты поумолчанию, по умолчанию там стандартное приветствие nginx
rm -f /etc/nginx/conf.d/default.conf
rm -f /etc/nginx/conf.d/virtual.conf
rm -f /etc/nginx/conf.d/ssl.conf# Приводим главный конфиг к подобному виду
mv /etc/nginx/nginx.conf /etc/nginx/nginx.conf.old
nano /etc/nginx/nginx.conf user nginx;
# Количество процессов ожидаюищих соединения
worker_processes 10;
pid /var/run/nginx.pid;
events {
# Максимальное количество обслуживаемых клиентов онлайн
worker_connections 1024;
# epoll — эффективный метод, используемый в Linux 2.6+ https://nginx.org/ru/docs/events.html
use epoll;
# Рабочий процесс за один раз будет принимать сразу все новые соединения
multi_accept on;
}
error_log /var/log/nginx/error.log warn;
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
connection_pool_size 256;
client_header_buffer_size 4k;
client_max_body_size 100m;
large_client_header_buffers 8 8k;
request_pool_size 4k;
output_buffers 1 32k;
postpone_output 1460;
# Все страницы будут ужиматься gzip
gzip on;
gzip_min_length 1024;
gzip_proxied any;
gzip_proxied expired no-cache no-store private auth;
gzip_types text/plain text/xml application/xml application/x-javascript text/javascript text/css text/json;
gzip_comp_level 5;
gzip_disable "MSIE [1-6]\.(?!.*SV1)";
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 75 20;
server_names_hash_max_size 8192;
ignore_invalid_headers on;
server_name_in_redirect off;
proxy_buffer_size 8k;
proxy_buffers 8 64k;
proxy_connect_timeout 1000;
proxy_read_timeout 12000;
proxy_send_timeout 12000;
# Мы рассказываем где будет храниться кеш, но по умолчанию я его не использую
proxy_cache_path /var/cache/nginx levels=2 keys_zone=pagecache:5m inactive=10m max_size=50m;
# Передаем backend реальный адрес клиента для mod_rpaf
real_ip_header X-Real-IP;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
allow all;
include /etc/nginx/conf.d/*.conf;
}
# Теперь приведем в порядок наш универсальный vhost
nano /etc/nginx/conf.d/all.confupstream web {
# Перечисляем все backend между которыми nginx будет балансировать клиентов, говорим количество fail для баны backend ноды и таймаут
# back01
server 10.211.77.131 weight=10 max_fails=60 fail_timeout=2s;
# back02
server 10.211.77.136 weight=10 max_fails=60 fail_timeout=2s;
}
server {
listen 80;
location / {
proxy_pass https://web;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
# И наш конфиг для работы сайта по SSL, для кажого сайта должен быть свой конфиг со своим сертификатом
nano /etc/nginx/conf.d/ssl.conf upstream ssl {
# back01
# server 10.211.77.131 weight=10 max_fails=60 fail_timeout=2s;
# back02
server 10.100.100.63 weight=10 max_fails=60 fail_timeout=2s;
}
server {
listen 443;
ssl on;
ssl_certificate /etc/nginx/ssl/GeoTrustCA.crt;
ssl_certificate_key /etc/nginx/ssl/GeoTrustCA.key;
# Увеличиваем безопасность нашего SSL соединения
ssl_ciphers RC4:HIGH:!aNULL:!MD5:!kEDH;
ssl_session_cache shared:SSL:10m;
ssl_prefer_server_ciphers on;
ssl_protocols SSLv3 TLSv1;
location / {
proxy_pass https://ssl;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}# Запускаем nginx и добавляем его в автозагрузку!
/etc/init.d/nginx start && chkconfig nginx on https://habrahabr.ru/company/acronis/blog/198934/