Fluentd: быстрый поиск логов с Elasticsearch, Kibana and Fluentd.
Содержание:
- Введение
2. Вариант 1 – реализация через fluentd agregator+fluentd forwarders
2.1 Установка Elasticsearch
2.2 Установка Kibana
2.3 Установка Fluentd
2.3 Настройка отправителей логов(fluentd-senders) во fluentd agregator
3. Вариант 2 – Rsyslog nodes > Rsyslog Agregator+fluentd+elasticsearch+kibana
4 Использование системы
5 Заключение
1 Введение.
Elasticsearch(версии 2.3): Elasticsearch является гибким и мощным решением с открытым исходным кодом, задачей которой является распространение, поиск в реальном времени и аналитика полученных данных . Благодаря разработке архитектуры с нуля для использования в распределенных средах, где надежность и масштабируемость должны иметь главное значение, Elasticsearch дает возможность легко выйти за рамки простого полнотекстового поиска. Благодаря своей прочной набор API-интерфейсов и запросов, DSL, плюс клиенты для наиболее популярных языков программирования, Elasticsearch поставляет на в будущем безграничные возможности в организации технологии поиска.
Kibana (послед версия 4.5): Kibana является визуализатором данных движка Elasticsearch, что позволяет нам изначально взаимодействовать со всеми данными в Elasticsearch через пользовательские инструментальные панели. динамические панели Kibana могут сохранятся, разделяться и экспортироваться, отображать изменения запросов в Elasticsearch в режиме реального времени. Вы можете выполнять анализ данных в пользовательском интерфейсе Kibana, используя заранее разработанные инструментальные панелей или обновлять эти панели мониторинга в режиме реального времени для анализа данных по лету.
Fluentdtd-agent v2.3.1): Fluentd является решением с открытым исходным кодом для сбора данных которое позволяет унифицировать сбор данных для большего понимания и удобства дальнейшего анализа.
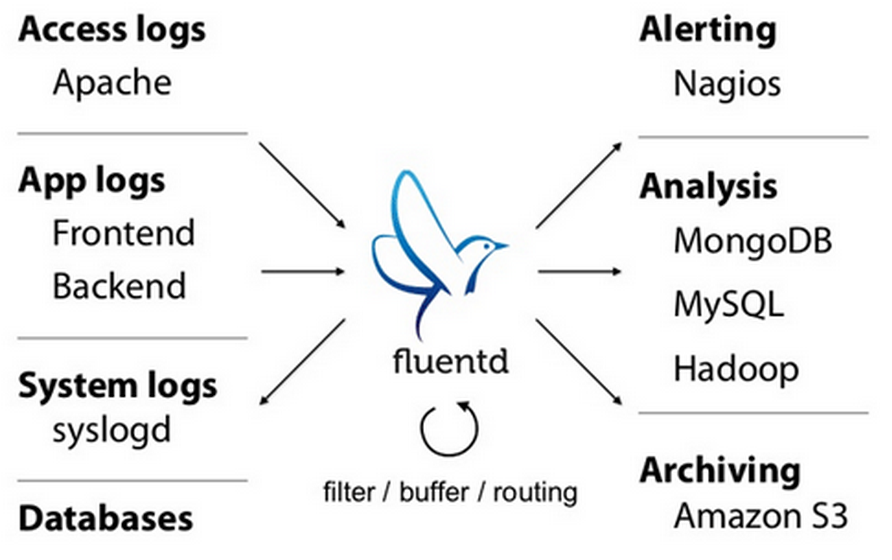
Я представил один из вариантов системы – для возможности разрешения конфликтов в зависимостях.
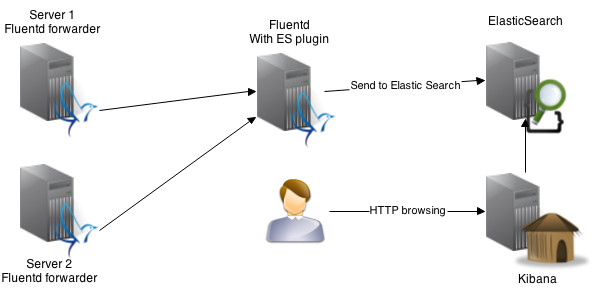
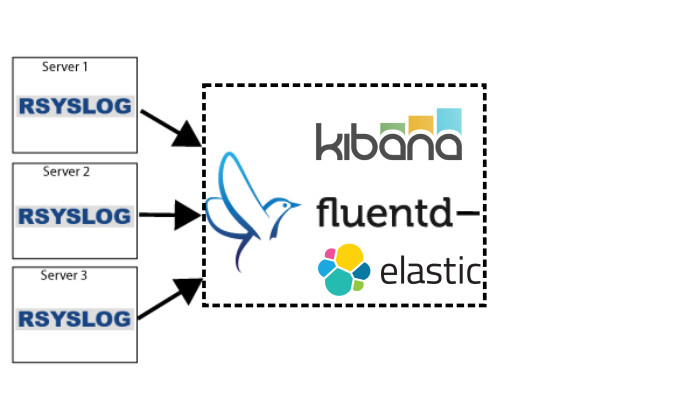
Кратко смысл всей системы – rsyslog(стандартная системная утилита для логирования действий в linux) является “форвардером” логов во Fluentd. Fluentd в свою очередь обрабатывает и агрегирует эти логи(собирает их с других машин) Далее elasticsearch обрабатывает все логи, полученные из fluentd(c помощью плагина), а благодаря Kibana мы получаем всю это информацию в красивой обертке через веб-морду. Это мы будем иметь в итоге.
Наша конфигурация, которую мы будем иметь в итого будет отличаться, от верхней схемы и будет иметь следующий вид:

Т.е. мы будем иметь одну главную машину для сбора, агрегации и вывода логов через web морду Kibana.
2 Вариант 1 – реализация через fluentd agregator+fluentd forwarders
2.1 Установка – подготавливаем сервер сбора логов.
Информация.
На сервер мы установим fluentd, elasticsearch plugin,elastic search, kibana. Всё тестировалось на dedian 8. Назовем нашу машину – logserver. IP – 10.4.1.174
Linux logserver 3.16.0-4-amd64 #1 SMP Debian 3.16.7-ckt20-1+deb8u4 (2016-02-29) x86_64 GNU/Linux. Итак, приступим к установке.
Elasticsearch
На данный момент последней версией является 2.3.0 – её мы и установим.
Для начала устанавливаем java:
sudo su
echo "deb https://ppa.launchpad.net/webupd8team/java/ubuntu trusty main" | tee /etc/apt/sources.list.d/webupd8team-java.list
echo "deb-src https://ppa.launchpad.net/webupd8team/java/ubuntu trusty main" | tee -a /etc/apt/sources.list.d/webupd8team-java.list
apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys EEA14886
apt-get update
apt-get install oracle-java8-installer
Устанавливаем сам elasticsearch 2.3.0
https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/deb/elasticsearch/2.3.1/elasticsearch-2.3.1.deb
dpkg -i elasticsearch-2.3.1.deb
После установки добавляем в автозапуск
update-rc.d elasticsearch defaults 95 10
/bin/systemctl daemon-reload
/bin/systemctl enable elasticsearch.service
Отредактируем файл /etc/elasticsearch/elasticsearch.yml
nano /etc/elasticsearch/elasticsearch.yml
Укажем , что никто по сети не мог читать наши данные(если необходимо)
path.data: /elasticdata path.logs: /elasticlogs network.host: localhost Сохраняемся. Создаем каталоги для данных mkdir /elasticdata mkdir /elasticlogschown -R -v elasticsearch:elasticsearch /elasticdata chown -R -v elasticsearch:elasticsearch /elasticlogssudo service elasticsearch restart
Установка kibana 4.5
Устанавливать Kibana будем из репозитория. Последняя версия 4.5
Добавляем ключ:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Создадим source list:
echo "deb https://packages.elastic.co/kibana/4.5/debian stable main" | sudo tee -a /etc/apt/sources.list
Обновимся
apt-get update
Установим Kibana через команду
apt-get -y install kibana
Кибана 4.5 установлена. Добавим ее в автозагрузку
update-rc.d kibana defaults 95 10
/bin/systemctl daemon-reload /bin/systemctl enable kibana.service
Откроем файл для настройки
nano /opt/kibana/config/kibana.yml
Укажем ip, на котором будет сидеть Kibana. Можете указать свой ип в сети(для этого поставим 0.0.0.0). Так же укажем url elasticsearch.
server.host: "0.0.0.0"
elasticsearch.url: "https://localhost:9200"
Kibana и Elasticsearch динамический поиск
By default, Elasticsearch enables dynamic mapping for fields. Kibana needs dynamic mapping to use fields in visualizations correctly, as well as to manage the .kibana index where saved searches, visualizations, and dashboards are stored.
If your Elasticsearch use case requires you to disable dynamic mapping, you need to manually provide mappings for fields that Kibana uses to create visualizations. You also need to manually enable dynamic mapping for the .kibana index.
The following procedure assumes that the .kibana index does not already exist in Elasticsearch and that the index.mapper.dynamic setting in elasticsearch.yml is set to false:
- Запустить elaticsearch
Создать файл индекса .kibana с динамическим отображением включенным только для этого индекса
PUT .
kibana { “index.mapper.dynamic”: true }
- Start Kibana and navigate to the web UI and verify that there are no error messages related to dynamic mapping.
Подключаем Еластиксёарч с Кибана
Before you can start using Kibana, you need to tell it which Elasticsearch indices you want to explore. The first time you access Kibana, you are prompted to define an index pattern that matches the name of one or more of your indices. That’s it. That’s all you need to configure to start using Kibana. You can add index patterns at any time from the Settings tab.
Рестартим kibana Смотрим нашу Kibanu в браузере https://<kibana_dns_name>:5601
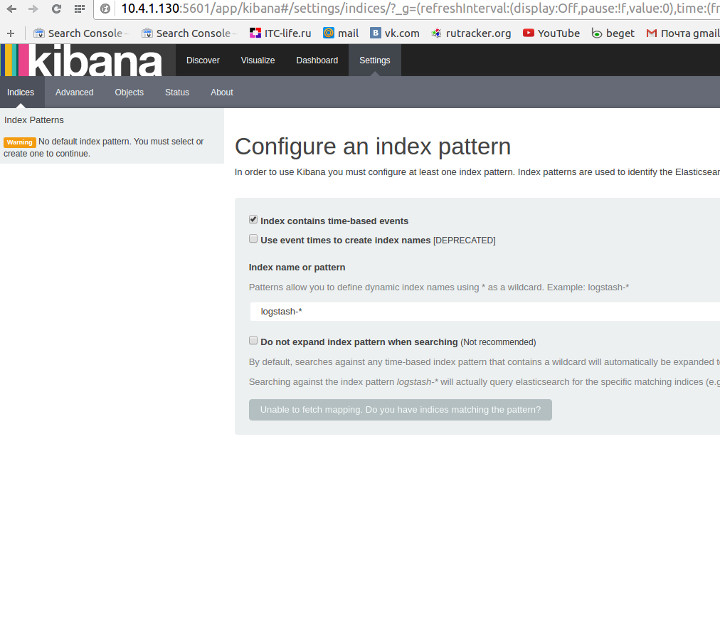
Fluentd(td-agent) install (debian jessie)
Флюенд это последняя часть нашей системы, он будет производить отправку логов или в другую систему fluentd или в elasticsearch. Устанавливаем на агрегаторе(ресивере) и форвардерах(отправителях). Для начала настроим систему чтобы она не стопорилась.
sudo nano /etc/security/limits.confroot soft nofile 65536 root hard nofile 65536 * soft nofile 65536 * hard nofile 65536
Оттюнингуем sysctrl.conf
sudo nano /etc/sysctl.conf net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.ip_local_port_range = 10240 65535
Применяем конфигурацию:
sysctl -pСтавим необходимые пакеты пакеты:
sudo apt-get install curl -ycurl -L https://toolbelt.treasuredata.com/sh/install-debian-jessie-td-agent2.sh | shТеперь установим fluentd и создадим папку для конфигов (будем их дальше включать в данную папку для удобства – они подхватятся):
mkdir /etc/td-agent/config.dПо-умолчанию Fluentd не умеет работать с Elasticsearch. Чтобы решить эту проблему мы установим специальный плагин,ставим его на агрегатор Fluentd, не на форвардерах (отправителях логов), так как в нашей схеме форвардеры отправляют данные fluentd на агрегатор, а он уже отпраляет их в elasticsearch. Идём в терминал:
aptitude install build-essential ruby-dev libcurl4-openssl-dev make
/usr/sbin/td-agent-gem install fluent-plugin-elasticsearch
apt-get install make libcurl4-gnutls-dev --yes
/opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-elasticsearch
/opt/td-agent/embedded/bin/fluent-gem install fluent-plugin-record-reformerИзменяем конфигурационный файл. В нем мы укажем, что будем отправлять данные в elasticsearch, он у нас на одной машине, значит укажем localhost:
sudo nano /etc/td-agent/td-agent.conf<match *.**> type copy <store> type elasticsearch host localhost port 9200 include_tag_key true tag_key @log_name logstash_format true flush_interval 10s </store> </match> # подключаем сторонние конфиги для удобства) include config.d/*.conf
Реастартим сервис
service td-agent restartСоздадим конфиг, который будет собирать данные с других серверов(отправителей логов):
touch /etc/td-agent/config.d/receiver.confnano /etc/td-agent/config.d/receiver.confВставим следующий код туда
## built-in TCP input ## @see https://docs.fluentd.org/articles/in_forward <source> @type forward port 24224 bind 0.0.0.0 </source>
Сохраняемся.
Не забываем открыть порты( с них мы будем слушать логи, которые нам посылаю серверы)
apt-get install iptables-persistent -y
/sbin/iptables -A INPUT -i eth0 -p tcp --destination-port 24224 -j ACCEPT /sbin/iptables -A INPUT -i eth0 -p udp --destination-port 24224 -j ACCEPT
Сохраним их
iptables-save > /etc/iptables/rules.v4
Далее перейдем к настройке отправителей логов.
3 Установка – настраиваем отправители логов.
Fluentd(td-agent) может выступать в роли как агрегатора так и отправителя логов. Логи он будет брать из нативной системы логирования debian(ubuntu) – rsyslog. Для начала установим rsyslog, если его нет в системе:
sudo apt-get install rsyslog curl -y
Настроим rsyslog.
sudo nano /etc/rsyslog.conf
Добавим строку, она означает, что rsyslog будет отправлять данные на порт 42185, его будет слушать td-agent(fluentd). Дальше вы увидите, как это реализовано.
*.* @127.0.0.1:42185
Сохраняемся.
sudo systemctl unmask rsyslog.service
Перезапустим Rsyslog сервис.
sudo service rsyslog restart
Далее установим Fluentd(td-agent)
sudo curl -L https://toolbelt.treasuredata.com/sh/install-debian-jessie-td-agent2.sh | shТеперь установим fluentd и создадим папку для конфигов(будем их дальше включать для удобства):
sudo mkdir /etc/td-agent/config.d
sudo mkdir /var/log/td-agent/failedИзменяем конфигурационный файл. Этот пример я взял(частично) из другого конфига, в нем так же задействован вариант со сбором логов из apache, нам можно понять из конфига что он берет данные из rsyslog(выше мы настроили отправку на порт 42185.)
sudo nano /etc/td-agent/td-agent.conf # Listen to Syslog <source> type syslog port 42185 tag hostname.system </source> include config.d/*.conf
Создадим конфиг для отправки логов на наш сервер сбора логов(10.4.1.130) на порт 24224:
nano /etc/td-agent/config.d/forwarder.conf
<match ***> type forward send_timeout 60s recover_wait 10s heartbeat_interval 1s phi_threshold 16 hard_timeout 120s # buffer buffer_type file buffer_path /var/log/td-agent/buffer/ buffer_chunk_limit 8m buffer_queue_limit 4096 flush_interval 10s retry_wait 20s # log to es <server> host 10.4.1.74 </server> <secondary> type file path /var/log/td-agent/failed/ </secondary> </match>
Поменяем права на каталог с логами
sudo chown -R -v td-agent:td-agent /var/log/td-agent
Реастартим сервис
sudo service td-agent restartСохраняемся и рестартим td-agent.
sudo service td-agent restart
3. Вариант 2 – Rsyslog nodes > Rsyslog Agregator+fluentd+elasticsearch+kibana
Смысл данного варианта схемы в следующем – данные c серверов будет отправлять rsyslog на сервер агрегатор, на котором крутится fluentd+elastic+kibana.
Для реализации данной схемы на понадобится изменить конфиги на клиенских машинах и заодно удалить td-agent:
Изменим его до этого вида:
################# #### MODULES #### ################# module(load="imuxsock") # provides support for local system logging module(load="imklog") # provides kernel logging support #module(load="immark") # provides --MARK-- message capability # provides UDP syslog reception #module(load="imudp") #input(type="imudp" port="514") # provides TCP syslog reception #module(load="imtcp") #input(type="imtcp" port="514") # Enable non-kernel facility klog messages $KLogPermitNonKernelFacility on # provides TCP syslog reception #$ModLoad imtcp #$InputTCPServerRun 514 $WorkDirectory /rsyslog/work # default location for work (spool) files $ActionQueueType LinkedList # use asynchronous processing $ActionQueueFileName srvrfwd # set file name, also enables disk mode $ActionResumeRetryCount -1 # infinite retries on insert failure $ActionQueueSaveOnShutdown on # save in-memory data if rsyslog shuts down ########################### #### GLOBAL DIRECTIVES #### ########################### # # Use traditional timestamp format. # To enable high precision timestamps, comment out the following line. # $ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat # Filter duplicated messages $RepeatedMsgReduction on # # Set the default permissions for all log files. # $FileOwner syslog $FileGroup adm $FileCreateMode 0640 $DirCreateMode 0755 $Umask 0022 $PrivDropToUser syslog $PrivDropToGroup syslog # # Where to place spool and state files # $WorkDirectory /var/spool/rsyslog # # Include all config files in /etc/rsyslog.d/ # $IncludeConfig /etc/rsyslog.d/*.conf
*.* @10.4.1.174:514
Вот так.
Теперь создадим файл отправки логов с другого сервиса, например с nginx при ошибке – error. Создадим файл nginx.conf в папке /etc/rsyslog.d
sudo mkdir /etc/rsyslog.d sudo nano /etc/rsyslog.d/nginx.conf
Вставим туда следующий код
$ModLoad imfile $InputFileName /var/log/nginx/error.log # or any log file on your server $InputFileTag nginxerror: # assign a unique tag so you can search on loggly easily $InputFileSeverity info $InputFileStateFile stat-nginx-error $InputRunFileMonitor # Include this so the imfile module will be able to scan the next file. #if $programname == 'nginxtest' then @@10.1.9.174
Это означает что все ошибка из файла на клиентской машине /var/log/nginx/error.log будут отправляться на сервер логов,там будет создаваться файл с название nginxerror.log (в папке с название хоста, как будет описано ниже). В итоге будет такая картина. Как у меня на примере в папке от хоста balance172 создается файл с ошибками nginx – nginxerror.ru
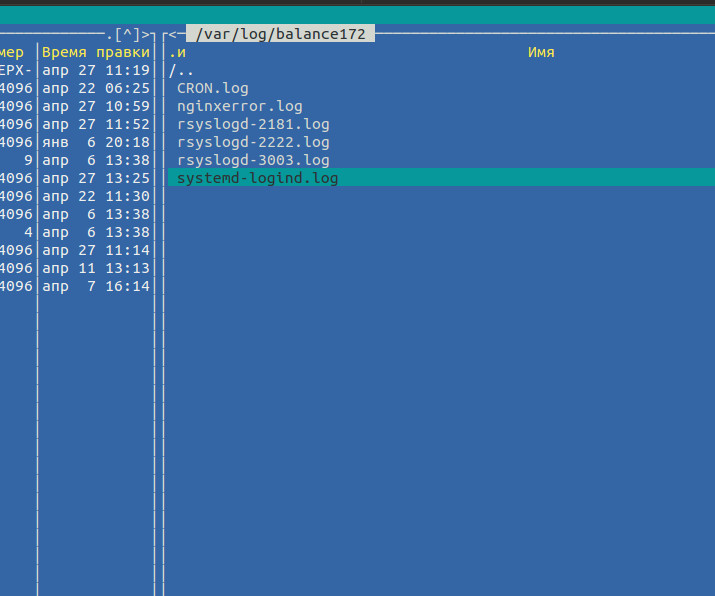
Перезапускаем клиентскую машину. 174 – ip сервера агрегатора.
sudo service rsyslog restart
На сервере(агрегаторе) вносим следующие изменения:
Редактируем файл /etc/rsyslog.conf для приема логов(по разным каталогам в зависимости от ip хоста). Раскомментим и добавим:
sudo nano /etc/rsyslog.conf
# provides UDP syslog reception $ModLoad imudp $UDPServerRun 514 # provides TCP syslog reception $ModLoad imtcp $InputTCPServerRun 514
# This one is the template to generate the log filename dynamically, depending on the client's IP address. #$template FILENAME,"/var/log/%fromhost-ip%/syslog.log" $template TmplAuth, "/var/log/%HOSTNAME%/%PROGRAMNAME%.log" $template TmplMsg, "/var/log/%HOSTNAME%/%PROGRAMNAME%.log" authpriv.* ?TmplAuth *.info,mail.none,authpriv.none,cron.none ?TmplMsg # Log all messages to the dynamically formed file. Now each clients log (192.168.1.2, 192.168.1.3,etc...), will be under a separate directory which is formed by the template FILENAME. *.* ?FILENAME
*.* @127.0.0.1:42185
Отредактируем файл /etc/td-agent/td-agent.conf
sudo nano /etc/td-agent/td-agent.conf
Приводим к такому виду:
<source> type syslog port 42185 tag system </source> <match *.**> type copy <store> type elasticsearch host localhost port 9200 include_tag_key true tag_key @log_name logstash_format true flush_interval 10s </store> </match> # подключаем сторонние конфиги для удобства) include config.d/*.conf
Удаляем все конфиги из папки /etc.td-agent/config.d/
sudo rm -r /etc/td-agent/config.d/*
Создаем только один файл там
mkdir /etc/td-agent/config.d/ nano /etc/td-agent/config.d/receiver.conf
Вставляем туда код
## built-in TCP input ## @see https://docs.fluentd.org/articles/in_forward <source> @type forward port 24224 bind 0.0.0.0 </source>
Откроем порты 514: apt-get install iptables-persistent -y
/sbin/iptables -A INPUT -i eth0 -p tcp --destination-port 514 -j ACCEPT /sbin/iptables -A INPUT -i eth0 -p udp --destination-port 514 -j ACCEPT iptables-save > /etc/iptables/rules.v4
Отредактируем файл
nano /etc/elasticsearch/elasticsearch.yml
укажем где будут храниться файлы:
path.data: /data # # Path to log files: # path.logs: /logs #
Хранить их в корне /data и /logs – вы можете выбрать другие. Назначим права.
mkdir /data mkdir /logs chown -R elasticsearch:elasticsearch /data chown -R elasticsearch:elasticsearch /logs
Рестартим все сервисы или быстрее сервак(как угодно).
sudo service td-agent restart
sudo service elasticsearch restart
5 Использование системы.
Переходим на сервер с kibana: https://kibana_ip:5601

Теперь вы можете попробовать создавать виджеты – как это делать ? Смотрим оф. доки на сайте the official documentation[4].
Можно узнать
а почему fluentd а не logstash ?
Если честно понравилась возможность расширения функциональности с помощью плагинов.
Интересно было попробовать новое решение, тем более Fluentd имеет хороший потенциал – расширяется плагинами, позволяющими реализовывать сбор информации, например анализ твиттов вашего бизнес аккаунта.
Для FLuentd больше расширений.
Доброго времени суток.
Подскажите а вам приходилось собирать логи java приложений типа tomcat или jboss? У меня возникла проблема что при сборе в kiban’е логи выводятся построчно, т.е. стектрейс идет не целым куском а каждая строка в новом сообщении, читать не очень удобно. К примеру:
вот так выглядит лог:
2016-09-22 21:50:00,411 ERROR [org.jboss.as.ejb3] (EJB default – 83) WFLYEJB0029: Could not restore timer from /opt/wildfly-app/standalone/data/timer-service-data/core-process.coreps-timers.ClearProcessDataTimer/77007d47-4375-46c0-9c2b-a081158361c7.xml: com.ctc.wstx.exc.WstxEOFException: Unexpected EOF in prolog
at [row,col {unknown-source}]: [1,0]
at com.ctc.wstx.sr.StreamScanner.throwUnexpectedEOF(StreamScanner.java:685)
at com.ctc.wstx.sr.BasicStreamReader.handleEOF(BasicStreamReader.java:2141)
at com.ctc.wstx.sr.BasicStreamReader.nextFromProlog(BasicStreamReader.java:2047)
а вот так его представляет Kibana :
September 22nd 2016, 18:46:21.000 host:xxx ident:java message: at org.wildfly.extension.requestcontroller.RequestController$QueuedTask$1.run(RequestController.java:496) @timestamp:September 22nd 2016, 18:46:21.000 _id:AVdSk5NjlfEFSA_UYhte _type:fluentd _index:logstash-2016.09.22 _score:
September 22nd 2016, 18:46:21.000 host:xxx ident:java message:2016-09-23 02:46:20,797 ERROR [org.jboss.as.ejb3] (EJB default – 149) WFLYEJB0029: Could not restore timer from /opt/wildfly-app/standalone/data/timer-service-data/core-process.coreps-timers.ConsRepTimerBean/72d64bed-09fa-44b1-b30a-e89001816a6b.xml: com.ctc.wstx.exc.WstxEOFException: Unexpected EOF in prolog @timestamp:September 22nd 2016, 18:46:21.000 _id:AVdSk5NilfEFSA_UYhsX _type:fluentd _index:logstash-2016.09.22 _score:
(логи я представил разные но общий смысл думаю понятен)
в данном случае хотелось бы чтоб весь стектрейс входил в поле message целиком и не делился на строки.
Может подскажете куда копать?
Заранее спасибо!