
Ceph is an open source storage platform which is designed for modern storage needs. Ceph is scalable to the exabyte level and designed to have no single points of failure making it ideal for applications which require highly available flexible storage.
The below diagram shows the layout of an example 3 node cluster with Ceph storage. Two network interfaces can be used to increase bandwidth and redundancy. This can help to maintain sufficient bandwidth for storage requirements without affecting client applications.
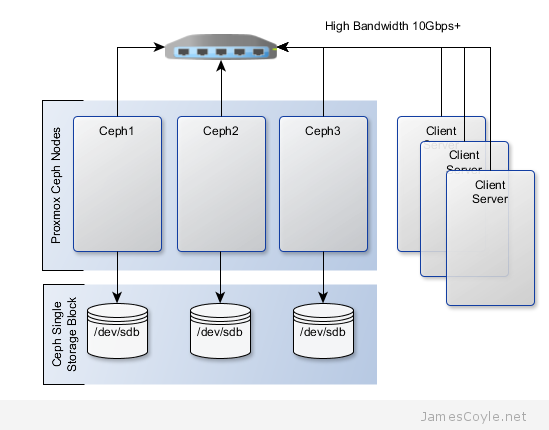
This example will create a 3 node Ceph cluster with no single point of failure to provide highly redundant storage. I will refer to three host names which are all resolvable via my LAN DNS server; ceph1, ceph2 and ceph3 which are all on the jamescoyle.net domain. Each of these nodes has two disks configured; one which runs the Linux OS and one which is going to be used for the Ceph storage. The below output shows the storage available, which is exactly the same on each host. /dev/vda is the root partition containing the OS install and /dev/vdb is an untouched partition which will be used for Ceph.
1 2 3 4 5 6 7 8 9 | root@ceph1:~# fdisk -l | grep /dev/vd Disk /dev/vdb doesn‘t contain a valid partition table Disk /dev/mapper/pve-root doesn’t contain a valid partition table Disk /dev/mapper/pve–swap doesn‘t contain a valid partition table Disk /dev/mapper/pve-data doesn’t contain a valid partition table Disk /dev/vda: 21.5 GB, 21474836480 bytes /dev/vda1 * 2048 1048575 523264 83 Linux /dev/vda2 1048576 41943039 20447232 8e Linux LVM Disk /dev/vdb: 107.4 GB, 107374182400 bytes |
Before getting started with setting up the Ceph cluster, you need to do some preparation work. Make sure the following prerequisites are met before continuing the tutorial.
- SSH Keys are set up between all nodes in your cluster – see this post for information on how to set up SSH Keys.
- NTP is set up on all nodes in your cluster to keep the time in sync. You can install it with: apt-get install ntp
You will need to perform the following steps on all nodes in your Ceph cluster. First you will add the Ceph repositories and download the key to make the latest Ceph packages available. Add the following line to a new /etc/apt/sources.list.d/ file.
1 | vi /etc/apt/sources.list.d/ceph.list |
Add the below entry, save and close the file.
1 | deb http://ceph.com/debian-dumpling/ wheezy main |
Download the key from Ceph’s git page and install it.
1 | wget –q –O– ‘https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc’ | apt–key add – |
Update all local repository cache.
1 | sudo apt–get update |
Note: if you see the below code when running apt-get update then the above wget command has failed – it could be because the Ceph git URL has changed.
1 | W: GPG error: http://ceph.com wheezy Release: The following signatures couldn’t be verified because the public key is not available: NO_PUBKEY 7EBFDD5D17ED316D |
Run the following commands on just one of your Ceph nodes. I’ll use ceph1 for this example. Update your local package cache and install the ceph-deploy command.
1 | apt–get install ceph–deploy –y |
Create the first Ceph storage cluster and specify the first server in your cluster by either hostname or IP address for [SERVER].
1 | ceph–deploy new [SERVER] |
For example
1 | ceph–deploy new ceph1.jamescoyle.net |
Now deploy Ceph onto all nodes which will be used for the Ceph storage. Replace the below [SERVER] tags with the host name or IP address of your Ceph cluster including the host you are running the command on. See this post if you get a key error here.
1 | ceph–deploy install [SERVER1] [SERVER2] [SERVER3] [SERVER...] |
For example
1 | ceph–deploy install ceph1.jamescoyle.net ceph2.jamescoyle.net ceph3.jamescoyle.net |
Install the Ceph monitor and accept the key warning as keys are generated. So that you don’t have a single point of failure, you will need at least 3 monitors. You must also have an uneven number of monitors – 3, 5, 7, etc. Again, you will need to replace the [SERVER] tags with your server names or IP addresses.
1 | ceph–deploy mon create [SERVER1] [SERVER2] [SERVER3] [SERVER...] |
Example
1 | ceph–deploy mon create ceph1.jamescoyle.net ceph2.jamescoyle.net ceph3.jamescoyle.net |
Now gather the keys of the deployed installation, just on your primary server.
1 | ceph–deploy gatherkeys [SERVER1] |
Example
1 | ceph–deploy gatherkeys ceph1.jamescoyle.net |
It’s now time to start adding storage to the Ceph cluster. The fdisk output at the top of this page shows that the disk I’m going to use for Ceph is /dev/vdb, which is the same for all the nodes in my cluster. Using Ceph terminology, we will create an OSD based on each disk in the cluster. We could have used a file system location instead of a whole disk but, for this example, we will use a whole disk. Use the below command, changing [SERVER] to the name of the Ceph server which houses the disk and [DISK] to the disk representation in /dev/.
1 | ceph–deploy osd —zap–disk create [SERVER]:[DISK] |
For example
1 | ceph–deploy osd —zap–disk create ceph1.jamescoyle.net:vdb |
If the command fails, it’s likely because you have partitions on your disk. Run the fdisk command on the disk and press d to delete the partitions and w to save the changes. For example:
1 | fdisk /dev/vdb |
Run the osd command for all nodes in your Ceph cluster
1 2 | ceph–deploy osd —zap–disk create ceph2.jamescoyle.net:vdb ceph–deploy osd —zap–disk create ceph3.jamescoyle.net:vdb |
We now have to calculate the number of placement groups (PG) for our storage pool. A storage pool is a collection of OSDs, 3 in our case, which should each contain around 100 placement groups. Each placement group will hold your client data and map it to an OSD whilst providing redundancy to protect against disk failure.
To calculate your placement group count, multiply the amount of OSDs you have by 100 and divide it by the number of number of times each part of data is stored. The default is to store each part of data twice which means that if a disk fails, you won’t loose the data because it’s stored twice.
For our example,
3 OSDs * 100 = 300
Divided by 2 replicas, 300 / 2 = 150
Now lets create the storage pool! Use the below command and substitute [NAME]with the name to give this storage pool and [PG] with the number we just calculated.
1 | ceph osd pool create [NAME] [PG] |
For example
1 2 | ceph osd pool create datastore 150 pool ‘datastore’ created |